本文共 5205 字,大约阅读时间需要 17 分钟。
- list
- tuple
- 条件判断
- 循环
- break和continue
- dict和set
- 不可变对象
附:
tuple是不变对象,把(1, 2, 3)和(1, [2, 3])放入dict或set中
(1)d={(1,2,3):1},没有报错{(1, 2, 3): 1}
(2)d={(1,[2,3]):1},报错
(3) s=set([(1,2,3)]),没有报错{(1, 2, 3)},注意,这里只有一个元素,即tuple(1,2,3)
(4)s=set([(1,[2,3])]),报错
dict和set的key都是不可变对象,和tuple的指向不变不一样,前者指的是可哈希和不可哈希
比如set()函数必须接受一个可迭代参数,如list, string, tuple等;并且该迭代器里的参数要可哈希。
(1,2,3)作为一个元组迭代器满足要求,(1,[2,3])满足迭代器的要求,但是[2,3]不满足可哈希的条件,所以会报错
# list:可变有序集合L1 = ['Bart', 'Lisa', 'Adam']# tuple:不可变有序列表#比如list中的1变为3,表面上tuple变了,但实际上tuple指向的list没变L2 = ('Bart', 'Lisa', [1, 2])# dict:key-value,key是不可变对象L3 = {'测试1': 95, '测试2': 75, '测试3': 85}# set:key,key不可变且不重复;而且要list作为输入集合L4 = set([1, 5, 3])
一:list(列表)
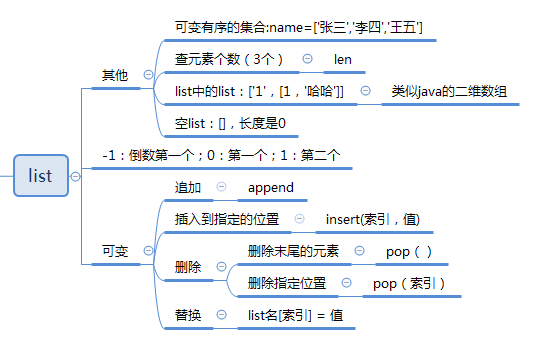
Python内置的一种数据类型是列表:list。list是一种可变有序的集合,可以随时添加和删除其中的元素
name=['张三','李四','王五']#结果['张三', '李四', '王五']print(name)#结果3print(len(name))#索引是从0开始print(name[0])#这种方法可以获取数组的最后一个元素,以此类推:-2就是倒数第二个print(name[-1])#IndexError:越界异常#追加字符,加在最后面name.append('黄月')#插入指定位置,如下面插在索引为1的位置name.insert(1,'陈二')#删除末尾的元素name.pop()#删除指定位置的元素,i是索引位置name.pop(1)#替换某个元素name[1]='换二' #list里面也可以有listname=['一维0',['二维0','二维1'],'一维2']#输出二维0print(name[1][0])
二:tuple(元组)

tuple和list非常类似,但是tuple一旦初始化就不能修改(不可变对象)
#一旦定义后就不能更改了name=('张玲','黄伊','陈二')#结果是('张玲', '黄伊', '陈二')print(name)#定义一个空的tuplename=()#定义只有一个元素的tuple#这种是错误的,输出的是1,因为有歧义,()可以是数学上的符号name=(1)#只有1个元素的tuple定义时必须加一个逗号,来消除歧义,输出是(1,)name=(1,)注意:name(3,)也是一个元素,3是name[0]的值
三:条件判断
#从上往下判断,如果在某个判断上是True,把该判断对应的语句执行后,就忽略掉剩下的elif和else#同理如果只有if-else,某一生效另一不执行a=5if a>10:#注意:缩进的两句都输出 print(1) print(2)elif a==10: print(3)else: print(4)#只要x是非零数值、非空字符串、非空list等,就判断为True,否则为Falseif x: print('True') #input()返回的数据类型是str,str不能直接和整数比较#修改方法,把str转换成整数#但是这样还有一个问题:int()函数发现一个字符串并不是合法的数字时就会报错,后续会学习到捕获异常可以int(input()) 也可以强制转换那个变量
四:循环
#for...in循环,可以将list或tuple中的元素迭代出来names=['张三','李四','王五']for name in names:#输出会换行 print(name)#range()函数,可以生成一个整数序列,再通过list()函数可以转换为list,从0开始#结果是[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]print(list(range(10)))
#while循环:只要条件满足,就不断循环,条件不满足时退出循环x=3while x>0: print(x) x=x-1#java可以i++;#python好像只能这样X += 1
五:break和continue[kənˈtɪnjuː]
# break语句会结束当前循环break
# continue语句会直接继续下一轮循环,后续的print()语句不会执行continue
死循环可以用Ctrl+C退出程序,或者强制结束Python进程
六:dict和set
(1)dict

Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map
使用键-值(key-value)存储,具有极快的查找速度,dict的key必须是不可变对象,这个通过key计算位置的算法称为哈希算法(Hash)
#理解:dict先内部算出测试1对应的内存地址,然后通过内存地址找到95d = {'测试1': 95, '测试2': 75, '测试3': 85}print(d)#也可以通过key放入值#一个key只能对应一个value,这里的10会把上面的95覆盖掉#如果d没有测试1这个key,就插入在后面d['测试1']=10#如果key不存在,dict就会报错#方法一:通过in判断key是否存在,有就是Trueprint('Bob' in d)#方法二:通过dict提供的get()方法,如果key不存在,可以返回None,存在就返回值print(d.get('Bob'))#也可以不存在的时候不返回None,返回一个自己指定的值print(d.get('a','没有值'))#要删除一个key,用pop(key)方法,对应的value也会从dict中删除print(d.pop('Bob')) dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法
要保证hash的正确性,作为key的对象就不能变。
在Python中,字符串、整数等都是不可变的,可以作为key。而list是可变的,不能作为key
#list是可变的,不能作为keykey=[0,1]d[key]='a'
附加:
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85, 'Tracy': 5}#结果{'Michael': 95, 'Bob': 75, 'Tracy': 5}print(d) 1: list和tuple其实是用链表顺序存储的,也就是前一个元素中存储了下一个元素的位置,这样只要找到第一个元素的位置就可以顺藤摸瓜找到所有元素的位置,所以list的名字其实就是个指针,指向list的第一个元素的位置。
(1)list的插入和删除等可以直接用链表的方式进行
比如我要在第1个元素和第2个元素中间插入一个元素,那么直接在链表的最后面(我们假设这个list只有两个元素,那么也就是在第3个元素的位置上)插入这个元素,然后把第一个元素指针指向这个元素(第3个位置),然后再把新插入的元素的指针指向原来的第2个元素,这样插入操作就完成了。
读取这个list的时候,先用list的名字(就是个指针,指向第1个元素的位置)找到第一个元素,然后用第1个元素的指针找到第2个元素(位置3),然后用第2个元素的指针找到第3个元素(位置2),以此类推。所以list的顺序和内存中的实际顺序其实不一定完全对应。这种存储方式不会浪费内存,但查找起来特别费时间,因为要按照链表一个一个找下去,如果你的list特别大的话,那么要等好久才会找到结果。
(2)dict则为了快速查找使用了一种特别的方法,哈希表。哈希表采用哈希函数从key计算得到一个数字(哈希函数有个特点:对于不同的key,有很大的概率得到的哈希值也不同),然后直接把value存储到这个数字所对应的地址上,比如key='ABC',value=10,经过哈希函数得到key对应的哈希值为123,那么就申请一个有1000个地址(从0到999)的内存,然后把10存放在地址为123的地方。类似的,对于key='BCD',value=20,得到key的哈希值为234,那么就把20存放在地址为234的地方。对于这样的表查找起来是非常方便的。只要给出key,计算得到哈希值,然后直接到对应的地址去找value就可以了。无论有几个元素,都可以直接找到value,无需遍历整个表。不过虽然dict查找速度快,但内存浪费严重,你看我们只存储了两个元素,都要申请一个长度为1000的内存。
2. 现在你知道为啥key要用不可变对象了吧?因为不可变对象是常量,每次的哈希值算出来都是固定的,这样就不会出错。比如key='ABC',value=10,存储地址为123,假设我突发奇想,把key改成'BCD',那么当查找'BCD'的value的时候就会去234的地址找,但那里啥也没有,这就乱套了。
3.你看我们上面有一句话:对于不同的key,有很大的概率得到的哈希值也不同。那么有很小的概率不同的key可以得到相同的哈希值了?没错,比如对于我们的例子来说,哈希值只有3位,那么只要元素个数超过1000,就一定会有至少两个key的哈希值相同(鸽笼原理),这种情况叫“冲突”,设计哈希表的时候要采取办法减少冲突,实在冲突了也要想办法补救。不过这是编译器的事情,况且对于初学者的我们来说碰到的冲突的概率基本等于零,就不用操心了。
(2)set

set和dict类似,也是一组key的集合,但set没有存储对应的value。由于key不能重复,所以,在set中,没有重复的key
#创建一个set,需要一个list作为输入集合name=set([1,1,5,3])#结果{1, 3, 5},重复的元素被自动过滤print(name)#添加元素到set中,可以重复添加,但不会有效果name.add(1)#删除元素name.remove(1)print(name)#&:交集;|:并集 set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。试试把list放入set,看看是否会报错。
#这样可以,[1,5,3]可是一个list啊???name1=set([1,5,3])#这样不可以name2=set(1,[5,3])#用一个list来初始化set,感觉就像是把这个list每个元素都扒开了往set里填,所以第一个全部数据就 1,5,3#但是第二个全扒开以后,元素 为 1,[5,3],第二个元素不符合set的特性,所以会初始化失败
七:不可变对象
str是不变对象,而list是可变对象
a=[1,5,3]#对list进行操作,list内部是会变化的,输出是[1, 3, 5]a.sort()print(a)a='abc'#对str进行操作,输出还是Abc,但是没有吧值赋值给一个变量,被python的垃圾回收机制清除了a.replace('a','A')#输出abcprint(a)b=a.replace('a','A')#输出Abcprint(b)

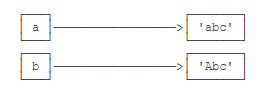
a是变量,而'abc'才是字符串对象!我们经常说,对象a的内容是'abc',但其实是指,a本身是一个变量,它指向的对象的内容才是'abc'
当我们调用a.replace('a', 'A')时,实际上调用方法replace是作用在字符串对象'abc'上的,而这个方法虽然名字叫replace,但却没有改变字符串'abc'的内容。相反,replace方法创建了一个新字符串'Abc'并返回,如果我们用变量b指向该新字符串,就容易理解了,变量a仍指向原有的字符串'abc',但变量b却指向新字符串'Abc'了
转载地址:http://fwsh.baihongyu.com/